
Cet article est une traduction de No, homeopathic remedies can’t “detox” you from exposure to Roundup: Examining Séralini’s latest rat study, publié sur le blog The Logic of Science.

Un des objectifs principaux de ce blog est de donner des outils au grand public pour évaluer les articles scientifiques. J’ai ainsi déjà écrit une série de billets où je dissèque des articles scientifiques et explique en quoi ils sont robustes ou au contraires peu fiables (voir par exemple les billets sur le Splenda, les OGM, les vaccins). Ces billets ont comme double objectif à la fois de faire du debunking de résultats scientifiques douteux mais également d’apprendre aux gens à penser de façon critique. Voici une occasion de revisiter le sujet. La semaine passée, quelqu’un m’a montré une récente étude censée, d’après mon interlocuteur, prouver que le détox est légitime et qu’il existe des remèdes naturels permettant au corps de se débarrasser des toxines. L’étude en question est « Dig1 protects against locomoter and biochemical dysfunctions provoked by Roundup ». Comme vous pouvez sans doute déjà l’imaginer, c’est un article qui n’a rien d’exceptionnel. À vrai dire, il est tellement mauvais qu’il m’a semblé être un excellent candidat pour illustrer toutes les choses auxquelles il faut être vigilant dans la lecture d’un article scientifique. Je vais résumer les points principaux ci-dessous, mais je vous encourage à lire le papier vous-même et tenter de repérer les problèmes qui s’y trouvent avant de continuer votre lecture.
J’ai tenté d’organiser ce post de façon progressive, en commençant par les problèmes plutôt légers, pour continuer ensuite sur des aspects qui limitent la portée des conclusions de l’article, et terminer enfin avec les problèmes qui invalident complètement ce papier. Cette progression reflète par ailleurs le degré de connaissance requis pour pouvoir détecter ces problèmes. La plupart des gens devraient être capables de repérer les premiers signaux d’alarme, donc même sans maitriser les statistiques plus avancées pour repérer les problèmes techniques, vous pouvez interpréter ces indices avant-coureurs comme une invitation à être prudent et ne pas accepter les conclusions sans une lecture critique et minutieuse.
Auteurs et conflits d’intérêt
C’est toujours un bon réflexe de jeter un œil aux auteurs et aux sources de financement. Certains scientifiques ont la réputation de publier des recherches de mauvaise qualité, voire frauduleuses, et vous devriez vous en méfier. De la même manière, des conflits d’intérêt financiers devraient déclencher en vous un regain de scepticisme face à l’article. Ceci étant dit, je tiens à être absolument clair : vous ne pouvez pas affirmer qu’une étude est fausse sur la seule base des auteurs ou conflits d’intérêt. Il s’agit de signes d’alarme qui doivent vous rendre critique et vous amener à lire plus attentivement l’article, mais ce ne sont pas en soi des arguments suffisants pour le rejeter (faire autrement reviendrait à commettre un ad hominem/sophisme génétique). Voyons les choses ainsi : si j’ai devant les yeux un papier dont certaines sections manquent de clarté, mais a été écrit par des scientifiques réputés n’ayant aucun conflit d’intérêt, je serais enclin à leur donner le bénéfice du doute. Par contre, si le même article a été écrit par des scientifiques de seconde zone et/ou avec de sérieux conflits d’intérêt, il est peu probable que je laisse la chose passer. Une autre considération générale à prendre en compte est le reste de la littérature. Des affirmations extraordinaires exigent des preuves extraordinaires, et il faut se montrer suspicieux des articles qui sont en conflit avec le reste de la littérature scientifique ont par ailleurs été écrits par des scientifiques marginaux et financés par des gens pouvant bénéficier des résultats publiés.
Maintenant que ces mises en garde ont été faites, jetons un œil au papier en question. La première chose qui saute aux yeux est que le dernier auteur est Gilles-Éric Séralini (la place de dernier auteur est habituellement réservée pour le scientifique senior responsable de la supervision du projet). Séralini, pour ceux qui l’ignorent, est connu pour ses publications médiocres et marginales anti-biotechnologie (en particulier les OGM). Il était en effet l’auteur principal de cette infâme étude sur des rats dont le but était de montrer que les OGM causaient le cancer, mais démontraient en réalité que Séralini ne comprenait rien au concept de groupe contrôle. L’étude était si mauvaise qu’elle a fini par être rétractée, après quoi Séralini la publia à nouveau dans un journal douteux qui n’a même pas pris la peine de le faire évaluer par les pairs (indigne d’un véritable scientifique).
Ce n’est pas ce qu’on appelle un bon début, mais ça ne s’améliore pas avec le financement. L’article parle des supposés bénéfices d’un produit homéopathique connu sous le nom de Digeodren (ou Dig1), mais a été financé par la firme qui commercialise le Digeodren (Sevene Pharma). Les auteurs tentent de noyer le poisson en affirmant : « Les auteurs déclarent n’avoir aucun conflit d’intérêt. Le développement de Dig1 par Sevene Pharma a été fait de façon tout à fait indépendante de son évaluation », mais ce n’est rien de plus qu’un leurre. Le fait que la production et l’expérimentation du Digeodren aient été séparées est sans importance. Le fait est que l’étude a été financée par la même firme qui produit le Digeodren et peut en tirer des bénéfices. C’est par définition un sérieux conflit d’intérêt.
Je rappelle cependant, afin d’être parfaitement clair, que je ne prétends pas que l’étude est invalide à cause du financement de Sevene Pharma, ou à cause de l’implication de Séralini. Mais ça n’empêche pas que ces deux éléments sont des signaux d’alarme, et le reste de l’étude a intérêt à être impeccable si on veut passer au-dessus.
Le journal ayant publié l’article
Une autre chose facile à identifier, c’est la qualité du journal qui a publié l’article. Il faut cependant être prudent avec cette approche parce qu’il existe de nombreuses recherches de bonne qualité qui sont publiées dans des journaux mineurs simplement en raison de l’étendue limitée du sujet traité ou d’un impact trop faible pour intéresser les grands journaux. La qualité du journal s’évalue donc à la hauteur des affirmations faites dans l’article. Autrement dit, si un article avance des affirmations extraordinaires mais a été publié dans un journal mineur, vous devriez lever un sourcil. Néanmoins, tout comme dans le cas des auteurs et des conflits d’intérêt, ce point n’est pas suffisant pour rejeter un papier, mais il doit tout même allumer quelques signaux.
Quid pour notre article ? Eh bien, il affirme non seulement qu’un remède homéopathique fonctionne (j’y reviendrai), mais qu’en plus il permet d’éliminer les toxines de votre corps. Ces deux affirmations extraordinaires vont à contre-courant d’une très large partie de la littérature scientifique. En d’autres termes, si de telles affirmations étaient solidement défendues, cet article serait d’un énorme intérêt et serait publié dans un journal majeur. Le fait qu’il se retrouve dans un journal marginal (BMC Complementary and Alternative Medicine) est à nouveau un signe qu’il y a quelque chose qui cloche.
Des affirmations extraordinaires requièrent des preuves extraordinaires
J’y ai déjà fait allusion plus haut : il faut toujours prendre en considération la plausibilité a priori des affirmations soutenues dans un article (autrement dit : étant donné le reste de la littérature, à quel point ces résultats sont-ils plausibles ?). Si un article rapporte des résultats similaires à des dizaines d’autres, il n’est pas nécessaire de se montrer critique à l’extrême (c’est toujours utile, mais de façon moins poussée). A contrario, lorsqu’un article rapporte des résultats qui entrent en conflit avec de nombreux autres papiers, il doit présenter des preuves extrêmement solides pour pouvoir les valider.
Dans notre cas, les affirmations sont effectivement assez extraordinaires. D’abord, il s’agit d’un test d’un remède homéopathique. J’ai déjà expliqué en long et en large les délires homéopathiques [NdT : autopromotion éhontée pour une référence en français de ma plume (de traducteur)], mais, pour faire court, l’homéopathie repose sur des notions absurdes comme le fait que des dilutions rendent le produit plus puissant, que des produits toxiques provoquant les mêmes symptômes que ceux dont vous souffrez peuvent vous soigner, ou encore que l’eau a une mémoire. En d’autres mots, l’homéopathie transgresse plusieurs concepts scientifiques fondamentaux extrêmement bien établis. Ça ne veut pas dire nécessairement que c’est faux car il est toujours techniquement possible (quoique très improbable) que ces concepts soient en fait erronés. Mais si c’est là votre argument, vous avez intérêt à fournir des preuves incroyablement robustes, et dans le cas de l’homéopathie, on est bien en peine de les trouver. En effet, des revues systématiques de la littérature montrent que l’homéopathie n’est rien de plus qu’un placebo. De même, les suppléments détox, cures de jus, bains de pieds, etc. sont des arnaques. Votre corps fait déjà son boulot pour garder à des niveaux sûrs des produits potentiellement dangereux, et aucun remède naturel n’a été prouvé capable de réellement éliminer des toxines.
Étant donné la montagne de preuves allant à l’encontre des affirmations faites dans ce papier, l’étude doit être exceptionnelle si elle veut être convaincante. Il lui faudrait des échantillons gigantesques, des contrôles extrêmement rigoureux, des statistiques robustes, etc. Autrement dit, la qualité méthodologique devrait atteindre un très haut niveau, mais y échoue complètement, comme je vais le montrer.
L’introduction et son importance
L’introduction d’un article (ici appelé « Background ») peut souvent en dire long. Les auteurs sont censés y faire un compte-rendu de l’état des connaissances sur le sujet traité et justifier l’intérêt et l’importance de leur étude. Lorsque les auteurs n’y parviennent pas, c’est souvent le signe de problèmes plus profonds.
En l’occurrence, l’introduction est très courte et contient quelques irrégularités. D’abord, parmi les références, nombreuses sont d’autres études de Séralini. Ce n’est pas un bon signe. Il y a une grosse partie de la littérature existante qui aurait dû être incluse (et qui est en désaccord avec Séralini). Certaines des études citées sont par ailleurs pour le moins contestables. L’un des arguments centraux repose en effet sur une citation de la fameuse étude OGM/rats susmentionnée, rétractée tan elle était bancale.
Méthodes : les essais sur animaux
Nous arrivons maintenant au cœur même de l’article, et la première chose qu’il faut souligner est qu’il s’agit d’un essai animal. Comme je l’ai plus longuement expliqué ici, les êtres humains ont une physiologie différente des autres animaux. Les études animales ne sont pas systématiquement applicables aux humains. Elles peuvent être utiles pour identifier de bons candidats de traitements à tester chez l’humain, mais vous ne pouvez pas affirmer que cela fonctionnera sur l’homme sur le seul fait que ça marche chez les rats. Pour être clair, je ne prétends pas par là que les résultats d’études animales sont faux. Il arrive en effet dans de nombreux cas que le médicament en question fonctionne effectivement chez l’animal étudié, mais cela ne signifie pas qu’il en sera de même chez l’humain. Par conséquent, vous devez être prudent à ne pas extrapoler automatiquement les résultats d’études animales aux êtres humains.
Méthodes : le design expérimental
Le design de l’étude était relativement simple. Ils ont pris un groupe de 160 rats et les ont répartis aléatoirement en quatre groupes de 40. Un groupe servait de contrôle et ne recevait aucun traitement, un groupe recevait du Roundup dans son eau, un groupe recevait du Digeodren, et le dernier groupe recevait à la fois du Digeodren et du Roundup dans son eau. Ce n’est pas une mauvaise idée, mais ce n’est pas non plus un design impeccable. Une meilleure approche aurait consisté à inclure un système de blocs.
Imaginez par exemple qu’il y avait un léger gradient de température dans l’animalerie, et les cages contenant les rats contrôle se trouvaient du côté plus froid. Cela introduit une nouvelle variable qui peut avoir des effets non négligeables sur l’étude. Vous seriez surpris à quel point des petits détails comme ça peuvent changer les résultats. C’est pour ça qu’un système de blocs aurait été une bien meilleure approche. Au lieu d’avoir quatre ensembles de cages, où chaque ensemble contient un groupe différent, vous mettez les membres de chaque groupe de traitement dans chaque ensemble de cages. Autrement dit, pour chaque ensemble de cages, vous sélectionnez aléatoirement 10 rats de chaque groupe de traitement, de sorte que chaque ensemble (chaque « bloc ») contient 10 individus de tous les groupes (la position des cages dans chaque bloc devrait également être choisie au hasard). Du coup, s’il y a un gradient de température (ou tout autre facteur confondant), il est neutralisé parce qu’il affecte tous les groupes de traitement de manière égale. Pour aller plus loin, vous pouvez (vous devriez, en réalité) inclure cette variable concernant les blocs dans vos analyses afin de réellement tester les facteurs confondants parmi vos ensembles de cages. Ne pas créer de blocs dans une telle expérience n’est pas nécessairement fatal à l’expérience (cela dépendra du type d’expérience), mais certainement cela donne moins confiance en ses résultats. Et je vous rappelle que pour accepter cet article en particulier, il doit être extraordinairement bon.
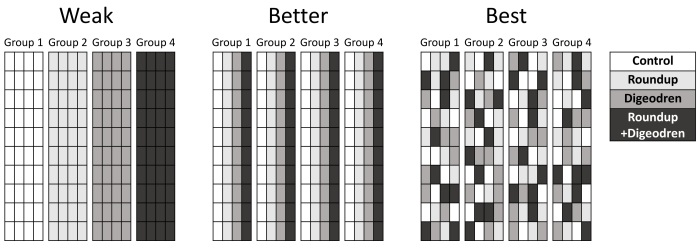
Un second problème concerne l’absence d’aveugle dans l’expérience : les chercheurs savaient quels rats étaient dans quel groupe de traitement. C’est une grosse faiblesse qui ouvre la porte des influences subtiles, involontairement motivées par les biais des chercheurs, d’autant que ceux-ci ont déjà une réputation de publier des articles idéologiquement chargés (j’insiste à nouveau, même une légère différence dans les conditions de vie des rats peut changer les résultats).
Note : les auteurs n’étaient pas très clairs sur la façon dont les cages étaient préparées, donc je ne suis pas certain du nombre de rats dans chaque cage ou du nombre de cages. Il est cependant évident qu’ils n’ont pas utilisé de répartition par blocs.
Méthodes : les doses
Chaque fois que vous lisez une étude de toxicologie, vous devez absolument faire attention aux doses pour vérifier qu’elles sont justifiées. Rappelez-vous que tout, même l’eau, est toxique à des doses suffisamment élevées. Lorsqu’une étude s’intéresse à un produit environnemental comme le Roundup, il est donc primordial qu’ils utilisent une dose à laquelle on pourrait raisonnablement être exposé dans l’environnement. Si ce n’est pas le cas, l’étude ne peut pas être extrapolée.
Dans cette étude, les rats du groupe Roundup ont reçu une dose de 135 mg/kg par jour. Une conversion en dose humaine nous donne l’équivalent d’une consommation de 21,9 mg/kg par jour. C’est gigantesque. La dose journalière admissible (DJA) du glyphosate (la molécule du Roundup) peut varier d’un pays à l’autre, mais elle est bien plus faible que ça. En Australie par exemple, elle est à 0,3 mg/kg, tandis que l’OMS la fixe à 1 mg/kg. La dose dans cette expérience est également bien au-delà des niveaux auxquels les gens peuvent être exposés. En étant très généreux et en acceptant les estimations discutables mises en avant par le « projet detox », qui pense que les américains ingèrent jusqu’à 3 mg/kg de glyphosate quotidiennement, la dose reçue par les rats est encore 7 fois plus élevée !
Soyons clairs, sur base de cette dose complètement irréaliste, cette étude ne vaut rien. Même si les auteurs avaient pu démontrer que le Digeodren avait le moindre effet face à ces niveaux, ça n’aurait en rien permis d’affirmer son utilité à des expositions normales au Roundup.
Méthodes : les statistiques
Nous en arrivons enfin au plus gros problème de cette étude (selon moi), celui qui l’invalide par lui tout seul. C’est une problématique que j’adresse souvent sur mon blog, les habitués voient probablement déjà où je veux en venir. Je veux parler des comparaisons multiples. En termes techniques, les auteurs n’ont pas contrôlé les taux d’erreur famille. La version grand public, c’est qu’ils ont fait tellement de comparaisons qu’il y en a eu l’une ou l’autre qui s’est révélée « significative » juste par hasard.
J’ai déjà écrit de longs billets sur le sujet, mais en gros, les tests statistiques standards tels que ceux utilisés par les auteurs se basent sur les probabilités afin de déterminer la significativité statistique. Les « p-values » rapportées désignent la probabilité d’obtenir un résultat dont l’effet est au moins aussi grand que celui réellement observé, sous l’hypothèse qu’il n’y a en fait aucun effet. Bien que non techniquement tout à fait correct, vous pouvez vous représenter cela comme la probabilité d’avoir un résultat positif juste par hasard. Dans le cas de l’article étudié ici, les p-values représentent les probabilités d’obtenir des différences plus grandes ou égales à celles des données observées, sous l’hypothèse que les traitements n’ont en réalité aucun effet. Définir ce qui est « significatif » revient à définir un seuil pré-défini qu’on nomme « alpha ». En biologie, la valeur alpha est le plus souvent égale à 0,05, ce qui signifie qu’une p-value plus petite que 0,05 sera considéré comme statistiquement significatif. Cependant, cette p-value de 0,05 signifie réellement qu’il existe une chance de 5% d’obtenir une différence de cette taille (ou plus grande) par pur hasard. C’est extrêmement important, parce que ça veut dire que vous obtiendrez de temps à autre des résultats « significatifs » par hasard, et nous appelons de tels résultats des erreurs de type I (ou erreurs de première espèce).
De là, on peut facilement entrevoir que plus les comparaisons sont nombreuses, plus le risque de tomber sur un faux positif augmente. En d’autres termes, si vous faites suffisamment de comparaisons, vous finirez par tomber sur des résultats significatifs par hasard. Votre taux d’erreur sur l’ensemble de vos tests est en fait bien plus grand que 0.05. C’est ce qu’on appelle le taux d’erreur famille, et il est d’une importance cruciale. Pour pallier ce problème, il y a au moins deux choses à faire. D’abord, dès la conception de votre étude, vous devriez avoir une idée claire des résultats attendus si votre hypothèse est correcte, et vous devriez vous limiter aux seules comparaisons nécessaires pour tester ces prédictions. Vous ne devriez pas faire tout un tas de comparaisons douteuses et espérer que quelque chose en ressortira. En second lieu, si vous devez avoir recours à des tests multiples afin de répondre à votre question (par exemple, est-ce que le médicament X fonctionne ?), vous devez alors contrôler le taux d’erreur famille en ajustant votre valeur alpha (le plus souvent via une correction de Bonferroni). En bref, votre alpha doit être de plus en plus petit au fur et à mesure que vous ajoutez des comparaisons.
Comment s’en sortent donc nos scientifiques intrépides à ce niveau ? C’est pas fabuleux. Ils ont fait énormément de comparaisons, 29 en tout, sur lesquelles 8 ont dépassé le seuil significatif, dont 6 seulement allant dans le sens d’un effet réel du Digeodren. Et bien sûr, ils n’ont pas contrôlé le taux d’erreur sur tous ces tests. Ils ont fait exactement ce qu’il ne fallait pas faire. Ils sont partis à la cueillette de cerises, pour trouver tout ce qui pourrait être significatif, au lieu de tester un ensemble restreint de prédictions bien définies. Ils ont fait tellement de comparaisons que certaines se sont retrouvées significatives par hasard. Pour le dire autrement, si j’avais fait cette expérience de façon exactement identique, sauf pour le fait de ne pas donner de Digeodren et Roundup, et si j’avais fait les mêmes 29 comparaisons sur les 4 groupes, je me serais attendu à obtenir quelques résultats significatifs, alors même que j’ai traité les 4 groupes de la même façon. Leurs résultats ne sont rien d’autres que des artefacts statistiques.
En plus, ils n’ont pas rapporté les p-values pour chaque comparaison, rendant ainsi impossible la vérification de leurs résultats (voir la note plus bas). S’ils avaient fourni un table de p-values comme ils auraient dû le faire, on aurait pu appliquer la correction de Bonferroni, mais comme ils ne l’ont pas fait, on ne peut rien faire de plus.
Pour être clair, dans de nombreux cas, le fait que des auteurs n’aient pas contrôlé leur taux d’erreur ne signifie pas automatiquement que leurs résultats soient des artefacts statistiques, par contre l’article n’est pas digne de confiance et devrait être rejeté. Ceci dit, dans notre cas, il faut tenir compte d’un facteur crucial : le fait que l’ensemble des preuves va à l’encontre de l’homéopathie. Lorsqu’on tient compte de toutes les preuves ainsi que de la faiblesse méthodologique de cette étude, la conclusion la plus rationnelle est que les résultats sont simplement faux et pas seulement douteux.
Note : si vous lisez l’article, vous verrez une référence à un test de Bonferroni ainsi qu’à des p-values, mais cela ne concerne que les tests individuellement et non la totalité des tests. En d’autres termes, les tests utilisés (ANOVA et Kruskal-Wallis) font des comparaisons entre plusieurs groupes (ici, les quatre groupes de traitement) et rapportent une p-value unique qui vous indique s’il existe au moins une différence significative entre les groupes. Et si c’est le cas, vous faites des comparaisons pairées et obtenez alors des p-values pour chaque comparaison. Ils ont reporté les p-values et contrôlé le taux d’erreur pour ces comparaisons entre elles au sein de chaque ANOVA, mais je parle bien ici des p-values entre toutes les ANOVA. En effet, il n’est pas indiqué des faire des comparaisons individuelles à moins que l’ANOVA soit elle-même significative, mais si vous ne contrôlez pas votre taux d’erreur entre les ANOVA (ce qui est critiqué ici), alors une grosse partie de vos ANOVA seront de faux positifs. Autrement dit, ils ont fait 29 tests ANOVA/Kruskal-Wallis, chacun d’entre eux comparant quatre groupes, puis ont contrôlé les taux d’erreurs pour les comparaisons subséquentes au sein des quatre groupes, mais pas entre les ANOVA mêmes.
Conclusion
En résumé, cet article est bourré de problèmes et ne vaut presque rien. Il est chargé de conflits d’intérêts, a été écrit par un auteur avec une réputation de publier des études douteuses et idéologiquement chargées, a été publié dans un journal de seconde zone, cite incorrectement et de façon incomplète la littérature, est basé sur un design expérimental qui laisse à désirer, n’a pas incorporé de procédures d’aveuglement, et (le plus important) a eu recours au nombre gigantesque de 29 comparaisons sans même prendre la peine de contrôler le taux d’erreur. Ce papier va à la pêche aux résultats significatifs. Les comparaisons étaient si nombreuses que certaines se sont révélées significatives par pur hasard. C’est une tactique courante chez les pseudoscientifiques (et malheureusement parfois chez les chercheurs aussi) et il est important d’apprendre à la repérer.

Bah, cette etude a le merite de mettre en evidence (en fallait-il plus?) que Seralini est un charlatan manipulateur (p = 0.0000001).
J’aimeJ’aime
C’est un bon article à ceci-près que j’aurais apprécié des exemples sur la partie des statistiques car j’ai du mal à comprendre.
J’aimeJ’aime
Il m’a semblé que les explications étaient relativement claires, mais si je peux aider à clarifier encore plus, je le fais volontiers. Quel passage en particulier vous semble compliqué?
J’aimeJ’aime
A reblogué ceci sur Des problèmes avec vos travaux universitaires?et a ajouté:
Les articles scientifiques, notamment dans le domaine de la biologie, vous paraissent souvent incompréhensibles? Notamment leurs statistiques? Voici la traduction d’un article qui propose un décryptage d’un tel article, y compris des calculs de probabilité et de statistiques qui y sont utilisés.
J’aimeJ’aime
Je n’ai pratiquement rien compris à la dernière note (celle juste avant la conclusion). C’est dommage parce que jusque là, j’arrivais à suivre sans le moindre problème… En tous cas, chouette article qui résume très bien de nombreux problèmes lié à une étude et à son interprétation. Merci pour la traduction…
J’aimeJ’aime
C’est vrai que ça devient un peu technique cette note. En gros, il y a eu des comparaisons multiples à plusieurs niveaux: d’un côté, il y a les 29 paramètres étudiés, mais pour chacun de ces paramètres, la comparaison se fait au sein de 4 groupes de traitement, et tu as de nouveau des comparaisons multiples au sein de ces 4 groupes (tu peux calculer une p-value pour une différence entre les 4 groupes, mais aussi pour chaque paire parmi les 4 groupes). Il y a eu des corrections pour le taux d’erreur famille à ce niveau-là (entre les 4 groupes), mais pas de correction, plus cruciale encore, entre les 29 paramètres étudiés.
J’aimeJ’aime
Excellent post. Merci.
Je suis allé voir l’article d’origine, en particulier la figure 2 qui montre la quantité vraiment importante, l’activité des animaux et j’ai remarqué quelque chose d’étrange : Les groupes contrôle et R+D ont des répartitions semblables, les groupes R et D aussi, à un niveau inférieur : le Digeodren a le même effet négatif que le Roundup. Le Roundup est un excellent détoxifiant contre le Digeodren. (je n’ai pas les moyens de vérifier la qualité statistique, mais l’impression est frappante)
J’aimeJ’aime
Merci pour ce billet. D’une manière générale, je râle aussi beaucoup contre les analyses statistiques qui sont faites dans les études de biologie. Il y a autant de façons de faire des stats qu’il y a de biologistes. Parcontre, j’ai quand même une remarque sur le test de Bonferroni. Je ne pense pas qu’il soit le plus approprié, car il est beaucoup trop conservateur (il divise l’alpha par le nombre de tests). La résultante est qu’il génère beaucoup de faux négatifs. Faire 29 ANOVA à 5% d’erreur admissible, ça revient à avoir en moyenne entre 1 et 2 faux-positifs. Il reste donc entre 6 et 7 effets (au niveau des ANOVA) détectés comme significatifs et très probablement réellement significatifs.
Concernant le plan en bloc, j’ai une question: comment faire un plan en bloc si aucun bloc n’est suspecté ? Pour moi, il aurait fallu faire 16 cages et les disposer de façon randomisée dans les emplacements prévus pour les recevoir.
J’aimeJ’aime
« Il reste donc entre 6 et 7 effets (au niveau des ANOVA) détectés comme significatifs et très probablement réellement significatifs. »
Si l’on tient compte de la plausibilité a priori, non, c’est très probablement des artefacts.
La correction de Bonferroni tend à être un peu conservatrice et donner des faux négatifs mais seulement pour les très grands nombres de comparaisons (par exemple les analyses génétiques ou de fMRI, où le nombre de tests peut atteindre plusieurs milliers). Ici, il est parfaitement approprié. En effet, le taux de faux positif (au moins un) sans correction est de 1-(1-0.05)^29 = 0.77, ce qui est énorme. Tandis qu’avec la correction de Bonferroni, on est à 1-(1-0.05/29)^29 = 0.0488, ce qui est très très près du 0.05 qu’on se donne habituellement (moins de 3% d’écarts). Donc je vois pas de raison fondamentale pour critiquer le fait d’utiliser une correction de Bonferroni ici.
Par contre, je n’ai pas compris ta question pour les blocs.
J’aimeJ’aime
Tu ne peux utiliser des blocs que SI tu as connaissance d’un gradient plausible. Sinon tu ne peux pas. Dommage que l’on ne puisse pas éditer.
J’aimeJ’aime
(J’ai supprimé le doublon)
Non, utiliser des blocs est toujours la méthode la plus robuste, précisément parce que tu ne peux pas nécessairement connaitre TOUS les potentiels facteurs confondants. Ce peut être un gradient de température, un flux d’air différent, un gradient d’humidité, une luminosité différente, etc. etc.
Plutôt que de tenter de mesurer tous les paramètres imaginables qui pourraient influencer les résultats, créer les blocs permet de s’en affranchir puisqu’on randomise les potentiels facteurs confondants.
J’aimeJ’aime
J’utilise le terme de bloc au sens des plans expérimentaux en agronomie. Parle-t-on bien de la même chose ? https://fr.wikipedia.org/wiki/M%C3%A9thode_exp%C3%A9rimentale
J’aimeJ’aime
C’est le même concept, sauf qu’ici on parle de l’emplacement des cages dans le labo et la façon de randomiser la présence des souris des différents groupes de traitements à travers ces cages (et blocs de cages). J’ignorais que ça s’employait également en recherche agronomique, mais ce n’est pas étonnant finalement. C’est un bon moyen de contrôler par la randomisation des potentiels facteurs confondants, sans avoir besoin de les identifier spécifiquement.
J’aimeJ’aime
j’avoue que la méthode des blocs, si je comprends bien une « randomisation » géographique censée pallier l’existence de facteurs eux aussi géographiques, ne me satisfait pas tout à fait, je ne vois qu’une méthode convenable pour pallier une éventuelle existence de paramètres géographiques …c’est de multiplier les dispositions..autrement dit de refaire l’expérience…
Dans les diagrammes que vous montrez aucun n’est plus « aléatoire » que les autres… et la résultante des effets d’un paramètre n’est pas forcement une égalisation des effets indépendante sur les différents groupes…
alors soit…en pratique comme les dits acteurs sont souvent associés à des gradients des trucs comme ça ..mélanger à partir d’un tirage au sort aléatoire semble intéressant….mais non….
A vrai dire une méthode de permutation des dispositions est meilleure…du moins me semble t il…
pas le choix si paramètres géographiques…refaire les tests en changeant la disposition.
bon c’est une critique qui pourrait porter sur beaucoup d’autres méthodes visant à s’affranchir de certains biais..en évitant le boulot…
Elle repose sur une curieuse connaissances des paramètres inconnus.
Au fait dans votre schéma…
imaginez un gradient vertical…
les résultats ne sont pas plus égalisés entre les groupes…
l’intérêt n’apparaît que si on multiplie les disposions.
Alors je comprends bien..si un effet faussement attribué dans une experience est du en fait à la géographie…une seconde tentative ( avec randomisation) par une autre équipe, conclura elle à l’absence d’effet. Car il y a peu de chance de retrouver une situation géographique similaire dans une seconde experience..sauf que c’est un peu aussi le cas si on ne randomise pas…
J’ai toujours du mal à voir l’intérêt d’une randomisation si elle ne se double pas de la multiplication des expériences à un point tel que je vois mal l’intérêt d’un expérience ou on ne fait dans le cas d’espèce qu’une disposition…fut elle randomisée.
J’aimeJ’aime
Refaire les expériences de manière indépendante est toujours une bonne idée. Honnêtement, le concept de la réplication est crucial en sciences, mais malheureusement il n’est pas assez « sexy » et ne se fait pas aussi souvent qu’il faudrait.
Ceci dit, je me demande si vous avez bien compris le principe des blocs. Le schéma ci-dessus est… schématique. Il ne parle pas de mettre littéralement côte à côte les cages des différents groupes. L’idée générale est de randomiser les positions de sorte à neutraliser de potentiels facteurs confondants (auxquels on n’aurait pas pensés).
Une seconde expérience non randomisée pourrait effectivement ne pas montrer les mêmes effets. Mais ce n’est pas sûr. Pourquoi se laisser une marge de doute alors qu’une simple procédure la réduit à zéro? Pourquoi gaspiller du temps et de l’argent à faire une expérience (la première aussi!) qui laisse la voie ouverte au doute?
J’aimeJ’aime
Je suis d’accord avec Jacques et c’est ce que j’essaie de t’expliquer depuis un petit moment: si tu n’as aucune idée d’un quelconque gradient, alors ta stratégie du plan en bloc ne repose sur absolument rien et tu ne peux, par définition, pas identifier de blocs. En l’absence de toute information sur un éventuel gradient, la réponse la moins pire est la randomisation totale. Eventuellement, le déplacement des cages peut être une bonne idée si ça ne fait pas plus de mal que de bien (stress par exemple).
En agronomie, les blocs reposent sur des faits clairement identifiés (l’effet parcelle par exemple). Il est donc aisé de faire des blocs. Dans le cas d’une pièce de labo, en principe, il n’y a pas d’effet bloc. Ou alors, c’est que la pièce est très mal conçue.
J’aimeJ’aime
« En l’absence de toute information sur un éventuel gradient, la réponse la moins pire est la randomisation totale. »
Oui, c’est bien ça que défend l’auteur.
Dire qu’il n’y a pas d’effet bloc dans un labo, c’est pas réaliste. Des pièces mal conçues, il y en a probablement autant que des pièces bien conçues. Surtout que, souvent, on peut pas mettre tous les rats dans la même pièce quand il y en a trop. Donc on se retrouve nécessairement avec des cages dans des pièces différentes, et donc des conditions différentes. La randomisation permet de mieux contrôler ce facteur confondant.
J’aimeJ’aime
Je voulais rajouter ceci aussi à propos des « effets clairement identifiés ». À mon sens, la randomisation va plus loin et s’attaque aussi à tout ce qui n’est pas identifié également. En recherche clinique, domaine dans lequel je travaille, la randomisation des patients sert à contrôler les facteurs confondants non identifiés également. Les facteurs identifiés sont explicitement utilisés comme facteurs de stratification, mais de manière générale la randomisation minimise aussi le risque qu’un facteur non identifié puisse perturber les résultats. La biologie humaine (et animale) c’est quand même très complexe, et on ne connait pas tout. C’est tout à fait raisonnable de faire la supposition qu’il puisse exister des facteurs confondants qu’on n’a pas encore identifiés, et donc de les contrôler par la randomisation.
J’aimeAimé par 1 personne
Merci pour ta réponse. Nous sommes bien d’accord.
J’aimeAimé par 1 personne
Un grand merci pour le temps passé à rédiger ce billet d’un très grand intérêt pour tous.
J’aimeAimé par 1 personne
[…] parce que c’est le cas de la plupart des travaux de Séralini (deux exemples récents ici et ici), mais contrairement à ce qu’on trouve dans la vaste majorité des études qui existent – […]
J’aimeJ’aime
Bonjour, merci pour ce très bon article 🙂
Merci aussi pour le temps consacré à la vulgarisation, la pensée scientifique est encore mal comprise, et j’ai souvent du mal moi aussi à mettre le doigt sur ce qui cloche. Sans compter le temps nécessaire pour décrypter, ou pour au moins s’informer sans se faire berner.
Petite remarque malgré tout : je trouve la partie statistique confuse. Sans être statisticienne, je suis un peu familière avec les tests d’hypothèses, j’ai bien compris ce que signifie la p value, donc assez bien le problème de multiplier les tests sans corriger le seuil. Mais même avec ce pré-requis je trouve que ce passage manque de clarté.
Bonne soirée et bonne fin d’année =)
J’aimeJ’aime
Merci pour ce retour.
Tu n’es pas la première à trouver la partie stats pas tout à fait claire. Cet article est une traduction, et j’essaie de rester bien sûr au plus proche de l’original. Je ne sais pas si la faute est dans l’original ou ma traduction (ou les deux), mais si tu as une question précise, je peux sans doute t’aider ici dans les commentaires.
bonne fin d’année également 🙂
J’aimeJ’aime
Excellent article, qui montre bien l’importance de la compréhension de la méthodologie pour pouvoir valider ou interpréter les conclusions d’une étude.
Je crois également important de vulgariser ces débats, même un peu techniques et vous félicite pour votre entière réussite en ce domaine.
J’aimeJ’aime